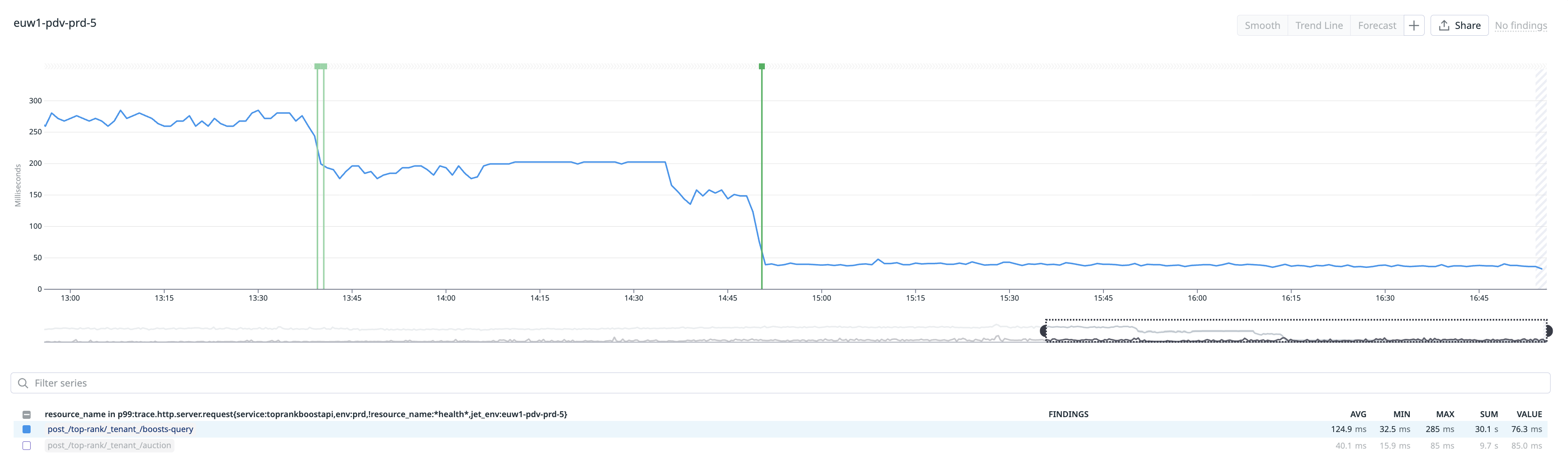
p99 latency before and after the sort key redesign.
The Problem
The Sponsored Campaign API serves boost scores for sponsored partners on a food delivery marketplace. Every time a consumer searches for restaurants on the app, the API is called with a list of partner IDs from the search results page (SERP) and needs to return which of those partners are running a sponsored campaign and what their boost score is. This needs to happen in single-digit milliseconds at high throughput across multiple markets.
Our V1 store architecture was designed around a geographic lookup model: “give me all the boosted partners in this delivery area at this time.” This worked well in markets where partners select specific delivery area zones for their campaigns. But in several other markets, a product decision was made to let partners simply select “all delivery areas” (represented as *). This one decision fundamentally broke the performance model.
The V1 Architecture
How the V1 Store Was Structured
The V1 DynamoDB table encoded the campaign schedule into the key structure:
- Partition key:
{tenant}#{deliveryDistrict}(e.g.de#BER-01orde#*) - Sort key:
{dayOfWeek}#{timeSlot}#{shardNumber}(e.g.Monday#lunch#1)
Each DynamoDB item contained a list of up to 1,000 boosted partners packed into a single document. When a shard filled up (hit the MaxPartnersPerShard limit of 1,000), a new shard was created – Monday#lunch#2, Monday#lunch#3, and so on. This sharding was necessary because DynamoDB has a 400KB item size limit, and with thousands of partners in popular markets, a single document would exceed that limit.
The write path was expensive too. When a single campaign event arrived from Kafka, the worker had to fan it out across every day-of-week and time-slot combination. A campaign active all week with all-day scheduling meant 7 separate DynamoDB items needed to be read, modified (adding the partner to the list), and written back. With specific time slots, that could be 7 days x 4 time slots = 28 items per campaign event. Each write used optimistic locking via a version attribute, meaning concurrent writes to the same shard could cause retries.
What the V1 API Was Actually Doing
When the API received a query with, say, 50 partner IDs from a SERP in a market using wildcard delivery areas, it would:
Fire off 4 parallel DynamoDB
Queryoperations usingbegins_withon the sort key to capture all shards:de#*+Monday#lunch(wildcard area, specific timeslot)de#*+Monday#all-day(wildcard area, all-day)de#{district}+Monday#lunch(specific area, specific timeslot)de#{district}+Monday#all-day(specific area, all-day)
Each query returned entire shard documents containing up to 1,000 partners each. In markets where virtually every sponsored partner was in the wildcard bucket, this meant pulling back every single boosted partner in the entire country.
The API then flattened all those shard lists and ran a post-filter: for each of the 50 requested partner IDs, it did a linear scan through the full list to check if that partner was boosted.
The Scale of the Problem
In one large market alone, the wildcard bucket regularly contained 11,000+ boosted partners. A request for 50 partners from a SERP would:
- Fetch all 11,000+ partners across multiple shard documents from DynamoDB
- Scan through them to find the 50 that were actually relevant
- Discard 99% of the data (10,950+ partners) that was never needed
There was no way to pre-filter this list because all the partners were packed into shared shard documents in DynamoDB. The partition key was the delivery area, and the sort key was the schedule – neither dimension included the partner ID. The only option was to fetch everything and filter in application code.
This architecture would have been perfectly fine had every market used the per-zone delivery area model. In markets with granular zones, a delivery district might contain 30-50 partners, making the “fetch all, then filter” approach nearly optimal. But when * became the default, all partners in a market collapsed into a single bucket.
The V2 Architecture
The Key Insight: Partner ID as the Sort Key
The fundamental redesign was inverting the key structure to make the partner ID a first-class citizen in the DynamoDB key:
- Partition key:
{tenant}#{deliveryDistrict}(same as V1) - Sort key:
{partnerId}(e.g.10740321)
Instead of packing thousands of partners into a single document organised by schedule, V2 stores one row per partner per delivery area. The schedule information (days of week, time slots) is stored as list attributes on each item rather than being encoded in the key structure.
This single change eliminated every problem:
- No more sharding. Each item is roughly 200 bytes (one partner’s boost data), well under the 400KB limit.
- No more write fan-out. A campaign event produces exactly 1 DynamoDB write instead of 7-28.
- No more post-filtering. The API can request exactly the partners it needs.
What the V2 API Does Now
When the API receives a query with 50 partner IDs from a SERP:
- It constructs exact key pairs:
(de#*, 10740321),(de#*, 10740322), … for each requested partner ID. - It issues a single
BatchGetItemrequest (or chunks of 100 if there are more partners, executed in parallel). - DynamoDB returns only the items that exist – at most 50 items, one per requested partner.
- A lightweight in-memory filter checks the
daysOfWeekandtimeSlotsattributes match the current time.
That’s it. Instead of fetching 11,000+ partners and discarding 99%, the API fetches exactly the 50 partners it cares about. The DynamoDB read is a direct key lookup – O(1) per item – rather than a scan across shard documents.
For markets using the wildcard model, the API knows to only query the {tenant}#* bucket. For markets where partners select specific zones, it queries both {tenant}#{district} and {tenant}#* in parallel and merges results, with area-specific entries taking priority.
The Expansion Manifest: A Path Not Taken
Before settling on the final V2 design, we explored an intermediate approach: an expansion manifest. The idea was that when a campaign was created with deliveryArea = "*", the worker would look up all the delivery areas that partner served (from our partner data) and expand the wildcard into explicit entries – one item per delivery area per partner.
This would have meant that a restaurant serving 15 delivery districts would get 15 items in the V2 table instead of 1 under *. The API could then query the specific bucket for that district and only find partners relevant to that area.
We built it, but ultimately abandoned it because:
- It shifted the write amplification problem rather than solving it. Instead of day/timeslot fan-out, we’d have delivery-area fan-out.
- Delivery area data could be stale. Partners change their delivery zones, and keeping an expansion manifest in sync added significant complexity.
- It didn’t actually solve the performance problem. In markets where delivery areas are small but some partners deliver to 3,000+ areas, most partners still appeared in most buckets. The read amplification dropped, but not dramatically.
The insight was that you don’t need geographic pre-filtering if you can filter by partner ID at the DynamoDB level – and the partner ID is the one thing the caller always knows.
The Numbers
| Metric | V1 | V2 | Improvement |
|---|---|---|---|
| DynamoDB items fetched per request | 11,000+ across shard docs | 50 (exact partner count) | ~220x less data |
| DynamoDB operations per request | 4 parallel Queries | 1 BatchGetItem | 4x fewer round trips |
| Post-filtering in app code | O(N*M) linear scan | O(N) dictionary lookup | Orders of magnitude |
| Write operations per campaign event | 7-28 items (day x timeslot) | 1 item | 7-28x fewer writes |
| Sharding complexity | Managed, with optimistic locking | None | Eliminated |
| p99 latency | ~100ms+ | ~10ms | ~10x improvement |
Technical Summary
| Aspect | V1 | V2 |
|---|---|---|
| Partition key | {tenant}#{deliveryDistrict} | {tenant}#{deliveryDistrict} |
| Sort key | {day}#{timeSlot}#{shard} | {partnerId} |
| Items per partner | 7-28 (day x timeslot x shards) | 1 |
| Partners per item | Up to 1,000 (shard list) | 1 |
| Read operation | Query + begins_with (scan) | BatchGetItem (direct lookup) |
| Schedule storage | Encoded in sort key structure | List attributes on each item |
| Write operation | Read-modify-write with optimistic locking | Single conditional PutItem |
| Write idempotency | Separate metadata table entries | Conditional expression: attribute_not_exists(sortKey) OR lastUpdated <= :ts |
The key takeaway: when your access pattern is “I know which items I want”, your key design should let you ask for them directly. The V1 store was optimised for the wrong question (“who are all the boosted partners in this area?”) while the V2 store is optimised for the right question (“are these specific partners boosted?”) since the caller already has the list of partner IDs from the search results.
This was one of those satisfying redesigns where the solution was conceptually simple – move the partner ID into the sort key – but the impact was dramatic. Sometimes the biggest performance wins come not from caching or scaling, but from asking “are we even querying the right way?”